I was an early adopter of OpenAI’s products back in 2022 and still remember showing my grandfather how the first version of Dall-E could create pictures out of just a bunch of words. (We still have a AI acrylic painting of a boat in his room)

From there I could see how ChatGPT would revolutionize certain aspects of my work back then, and also how could companies benefit from integrating it into their systems.
One the main use cases I could think of was data categorization and normalization like case formatting, typo corrections or translations. This stuck in my head in like forever and once I had access to tools like Zapier, then I felt my time had come to try what I had in my head for so long.
Current AI is far more poweful than in 2022 (with only 3 years difference!), it continues to evolve and amaze everyone. Same as the AI, my processes on data normalization and categorization changed throughout the time, and show the evolution of how an MVP can later turn into a great enhancement that is proper of the 21st century.
In here I’ll show my 3 different approaches on this duty, starting by a basic multi-step flow with the biggest prompt ever imaginable, to AI fine-tuned models capable of processing millions of tokens without even costing a dollar in the process.
To keep this simple, I’ll use the example of Job Title to Job Level categorization. However, these workflows can be applied to a variety of fields and cases.
Zapier Individual Approach
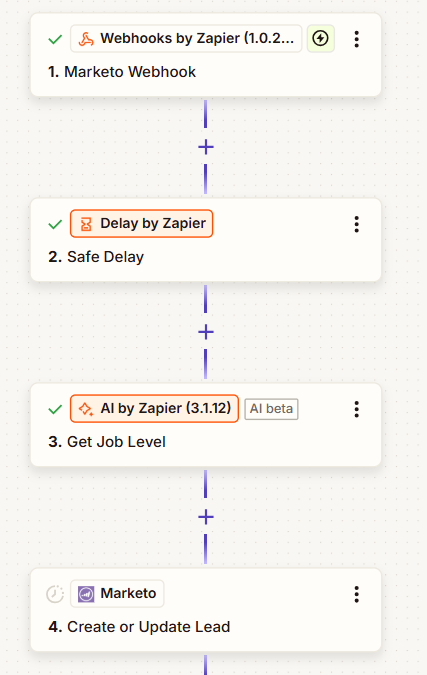
My first approach towards AI processing was through Zapier which, for those who may be living under a rock, is the most famous low-code automation platform in the market. Why it’s that famous is because of its simplicity and the vast amount of native API connections it has with other platforms.
My mental schema to normalize Job Levels using AI was fairly straightforward and settled the groundwork for the next versions:
- (New Lead AND Job Title is not Empty) OR (Job Title changes AND is not Empty)
- Runs a series of Marketo filters as a first layer
- If it finds a match, then happy days 😉
- If it doesn’t, then sends out a webhook to Zapier with Email and Job Title
- Runs a series of Marketo filters as a first layer
In Zapier, I’d then run the record through Zapier’s own AI, which to be honest was decent. It didn’t excel at nothing but it did the job, and the most important part I didn’t notice until later was that it didn’t matter how long the prompt was for the AI step.
The consequences of not being billed by the number of tokens I was sending and receiving was that trying to replicate the Zapier approach led to inefficient operational costs: if you have a 1500-token long prompt and you execute it for every incoming lead, that can result in tremendous unexpected costs at the end of the day.
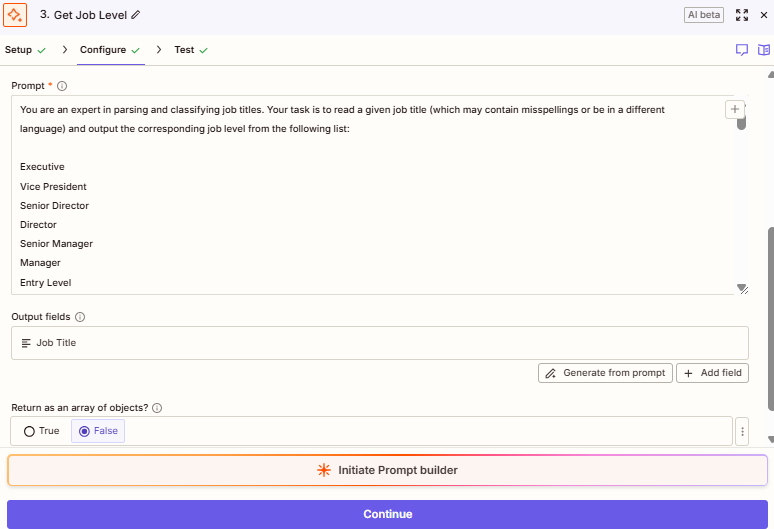
Nevertheless, back then it was much simpler and to my surprise, Zapier’s AI worked like a charm, allowing me to normalize on the spot every incoming lead who had an alien Job Title and then sync it back to Marketo using Zapier’s native step.
The problem with this workflow is that, as I have explained earlier, it was highly inefficient and consumed around 3-4 tasks per lead since there were some extra steps to prior cleanse the data or add it to a spreadsheet in case the AI failed to find a Job Level for the given title.
However, this Version 1 helped me to set up the mental framework for the upcoming workflows, which in my opinion are more effective and could result in better results.
Fun fact: this Zapier workflow was presented during my presentation at Madrid’s 3rd Marketo User Group. Not saying this workflow doesn’t work, it’s that now there are better ways to do the same work with a fraction of the cost.
N8N Bulk Approach
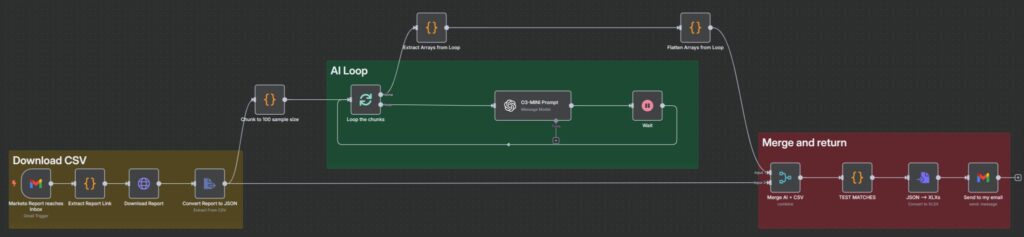
Similarly to Zapier, n8n is also a low-code automation platform able to host complex AI workflows. The perk with this platform as of today is that billing is not based on node execution but rather full workflow execution.
This of course sparked an idea in my brain and that was to do as many tasks in one workflow execution as possible, which meant processing all the new leads in bulk on a daily basis.
How this worked is, first you’ll have a list of all the leads of the day that Marketo wasn’t able to find a Job Level match and establish a list subscription to any email address you have access to.
Every day, the subscription would trigger and would send the list to your inbox. In my eyes, this is a trigger we can leverage. In n8n you can set up email inbox triggers for every new email received with a specific subject which for this case would be something like “Smart List Subscription – n8n Job Level Cleanup”.

Following that trigger, you’d need to download the CSV file and extract all the records in there. How n8n works is that each record would be an item, meaning that if we were to send the list as it is to the AI, it would repeat itself based on the number of items.
To solve that, we need to add a Code node to “merge” all the Job Titles into one big list, which we can later chop into chunks of 100 or 200 samples so the AI is able to manage that.
javascript
const items = $input.all();
const allTitles = items.map((item) => `"${item.json["Job Title"]}"`); // collect all job titles with extra ""
const batchSize = 200;
const output = [];
for (let i = 0; i < allTitles.length; i += batchSize) {
const chunk = allTitles.slice(i, i + batchSize);
output.push({
json: {
jobTitles: chunk, // Each item contains up to 200 job titles
},
});
}
return output;We then establish a Loop where we have the AI node with the same prompt we had in Zapier. The difference here is that now we’re processing several Job Titles in bulk in just one execution which lowers by a lot the associated costs with the AI model (which also in this case, we can choose the one we want).

After the Loop has run all the records, it’ll throw all the lists it processed which we can merge into one big array (same as the start).
javascript
// Initialize flat output array
let flattened = [];
// Go through all items
for (const item of items) {
const data = item.json;
for (const key of Object.keys(data)) {
const value = data[key];
// If it's an array with objects that have "Job Title"
if (Array.isArray(value) && value.length > 0 && typeof value[0] === 'object' && 'Job Title' in value[0]) {
flattened.push(...value);
}
}
}
// Return each job entry as its own item (for downstream nodes)
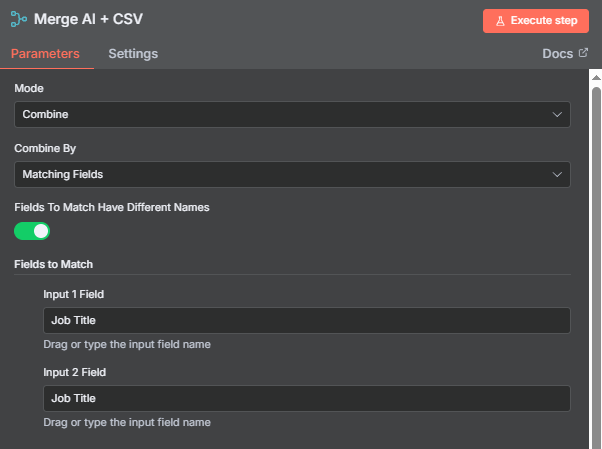
return flattened.map(entry => ({ json: entry }));How we can assign the corrected Job Level to the correct record is via the Merge node in n8n where we’ll use the Job Title as the unique identifier and finally, batch them back to Marketo or send us the list for a final review before we manually upload them. Both approaches are fine, depends on how accurate your AI prompt is.
Fine Tuned AI Approach

The final approach is sponsored by Tyron Pretorius in his blog post. In this case what we’re doing is leveraging an OpenAI model that has been previously trained with examples so it knows what to do in each case.
In my opinion, this method proves to be the best yet since it’s very cost-efficient and very easy to implement because it avoids using any third-party automation platforms like the ones mentioned.
However, I feel like this being the final approach instead of the first is important. With all the previous approaches what I was also doing was validating my prompt and fine-tuning it so it met the organization’s needs.
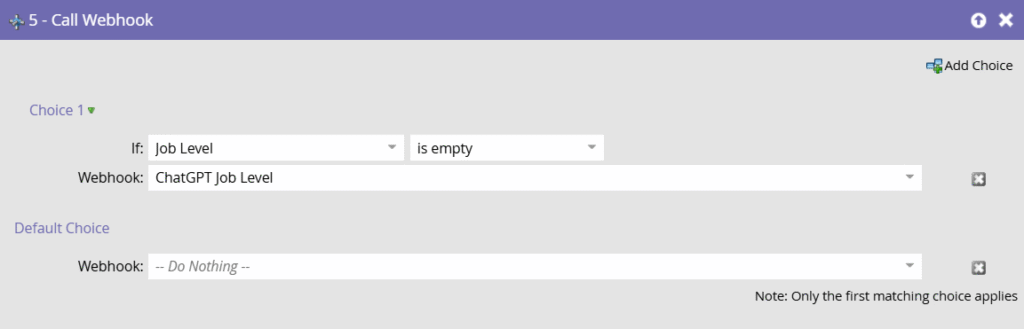
This resulted in a great database full of accurate examples which is just the source that the fine-tuned model needs. It’s like the logic of the prompt is already ingrained in all the records that went through Zapier’s and N8N’s workflows.
The lacking piece that I needed was to make it even more cost-efficient, and fine-tuned models solve this issue since we can leverage very cheap models like GPT-4o mini that have a negligible cost associated with it instead of the o3 or o1 models I was using back then for bulk processing ($0.10 per 1M input tokens and $0.40 per 1M output tokens).
I won’t explain much of how the implementation works, Tyron already does a great job doing it and it is easy to follow.
Just for the sake of archives, I’ll post my webhook Details (which differs from Tyron’s) so that other folks can copy it and tailor it to their needs just as I did with Tyron’s. Custom Headers and Response Mappings are the same as Tyron’s.
URL: https://api.openai.com/v1/chat/completionsPayload Template:
{
"model": "ft:gpt-4.1-nano-2025-04-14:nexhink:joblevel-250823:C7jkmBBd",
"temperature": 0.2,
"max_tokens": 2,
"messages": [
{
"role": "system",
"content": "Your job is to categorize the given job title into one of the following Job Levels: Executive, Vice President, Senior Director, Director, Senior Manager, Manager, Entry Level, Consultant, Analyst or (blank) if it's not a job title. If the job title qualifies for 2 job levels, choose the highest one."
},
{ "role": "user", "content": {{lead.Job Title}} }
]
}Request Encoding Token: JSONRequest Type: POSTRequest Format: JSON